Ethos
A behavioural-intelligence pipeline. Transcripts in; per-person tags with quoted evidence out.
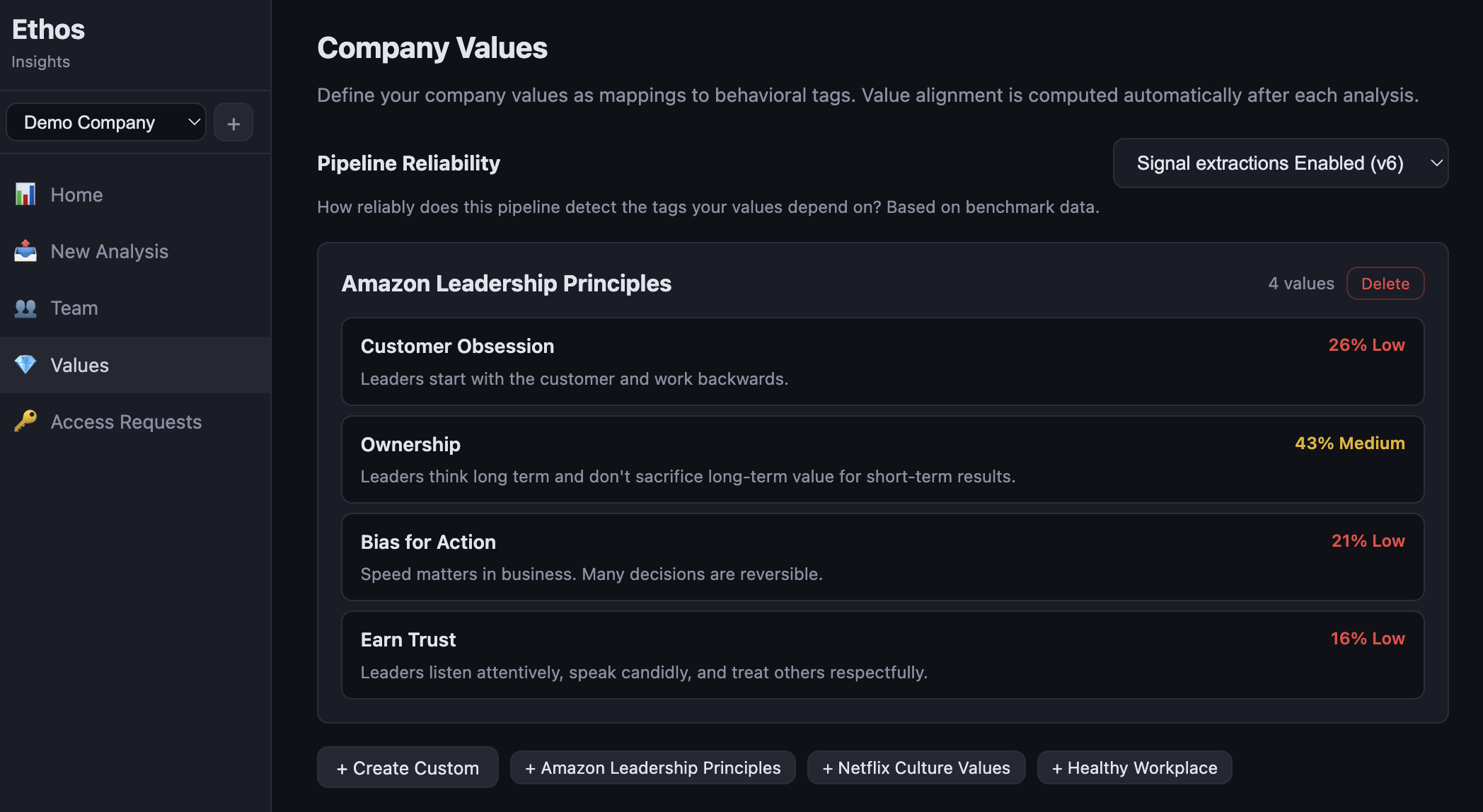
What Ethos does
Feed it a meeting transcript, a Slack thread, a sales call. The pipeline goes through six phases and returns, per participant in the conversation, a set of behavioural tags — "active listening", "defensiveness", "interruption", "facilitation" — each with a quoted message from the transcript and a confidence level on the claim. There's a single LLM call inside the pipeline, surrounded by validation and retry logic. The vocabulary the pipeline can use — the actual list of available tags — is something I control, not something the model decides on its own.
Two product surfaces share the same pipeline. There's a customer-facing app called Insights, where someone running a team sees per-person summaries and how their behaviour maps to whatever the company says it values. And there's a staff app where I do the engineering — design pipelines, build tag sets, run benchmarks, look at where the system is wrong.
Why I built it instead of buying something
Most products that promise behavioural analytics for teams come bundled into bigger HR platforms — Lattice, Culture Amp, that whole shape. The behavioural piece sits inside a $50–200/seat/year subscription, with a tag vocabulary the vendor picks and outputs you can't really inspect. Fine if you want a survey tool. Frustrating if what you actually want is a measurement instrument.
Ethos is what comes out when you build only the measurement instrument. Three weeks of focused work, a few hundred dollars in API spend, and you have a pipeline that ingests transcripts, applies a vocabulary you wrote, and produces measurements with quoted evidence behind every claim. Doesn't manage employees. Doesn't run engagement surveys. Doesn't talk to your HRIS. But for a company that already knows what it wants to measure, the trade-off looks different than it did a few years ago.
How it works
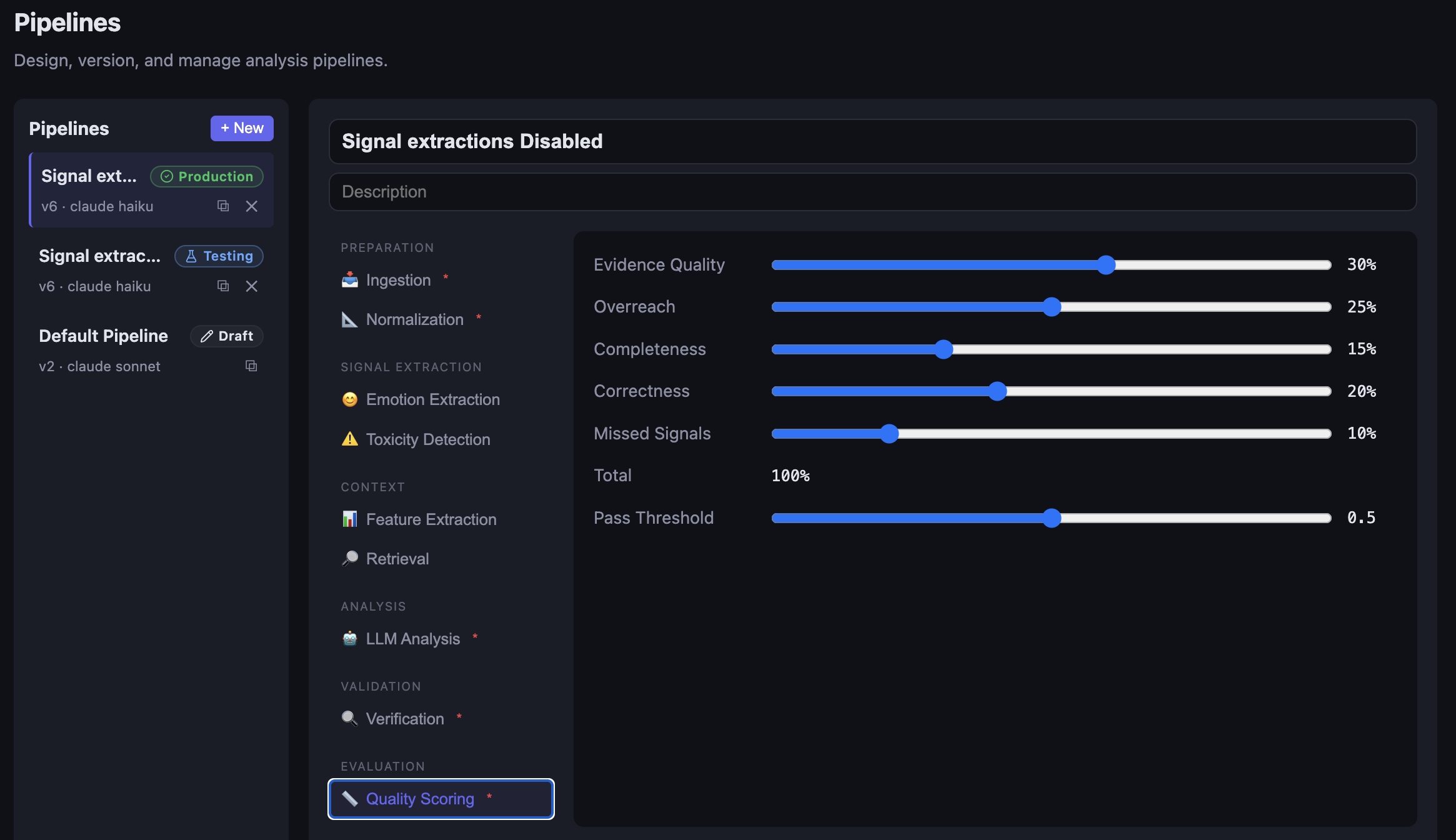
Six phases. Two LLM calls inside; the rest deterministic. Each step records its input, output, latency, token count, and cost, so a run is fully reconstructible after the fact.
transcript ─▶ ingest ─▶ normalise ─▶ signals ─▶ classify ─▶ analyse ─▶ evaluate ─▶ output
│ │ │ │
schema VADER + rules LLM Claude + Instructor
Ingest accepts whatever shape the transcript arrives in — text, JSON, VTT, Slack export. Normalise turns it into an indexed, schema-validated message stream. Signals runs deterministic tools over the messages: VADER for sentiment, separate models for toxicity and hedging, regex matching for facilitation events, plus per-speaker stats like talk-ratio and interruption count. None of it is LLM-driven. The output is a structured set of features.
Context classification is a small LLM call that tags the meeting type — sales call, 1:1, support ticket, standup, design review. The model uses this to calibrate the analysis. A raised voice in a customer support call means something different from a raised voice in an architecture-review debate.
Then the heavy step — behavioural analysis. Claude sees the indexed transcript, the precomputed signals, and the meeting context, and produces structured output through Instructor + Pydantic. The system prompt is mostly me telling Claude not to claim anything about a person without quoting a line from the transcript. When the output is missing a required field or cites a message index that doesn't exist, the call gets retried, up to three times. After that, evaluation runs schema and completeness checks and tags the run PASS, REVIEW, or FAIL.
The vocabulary
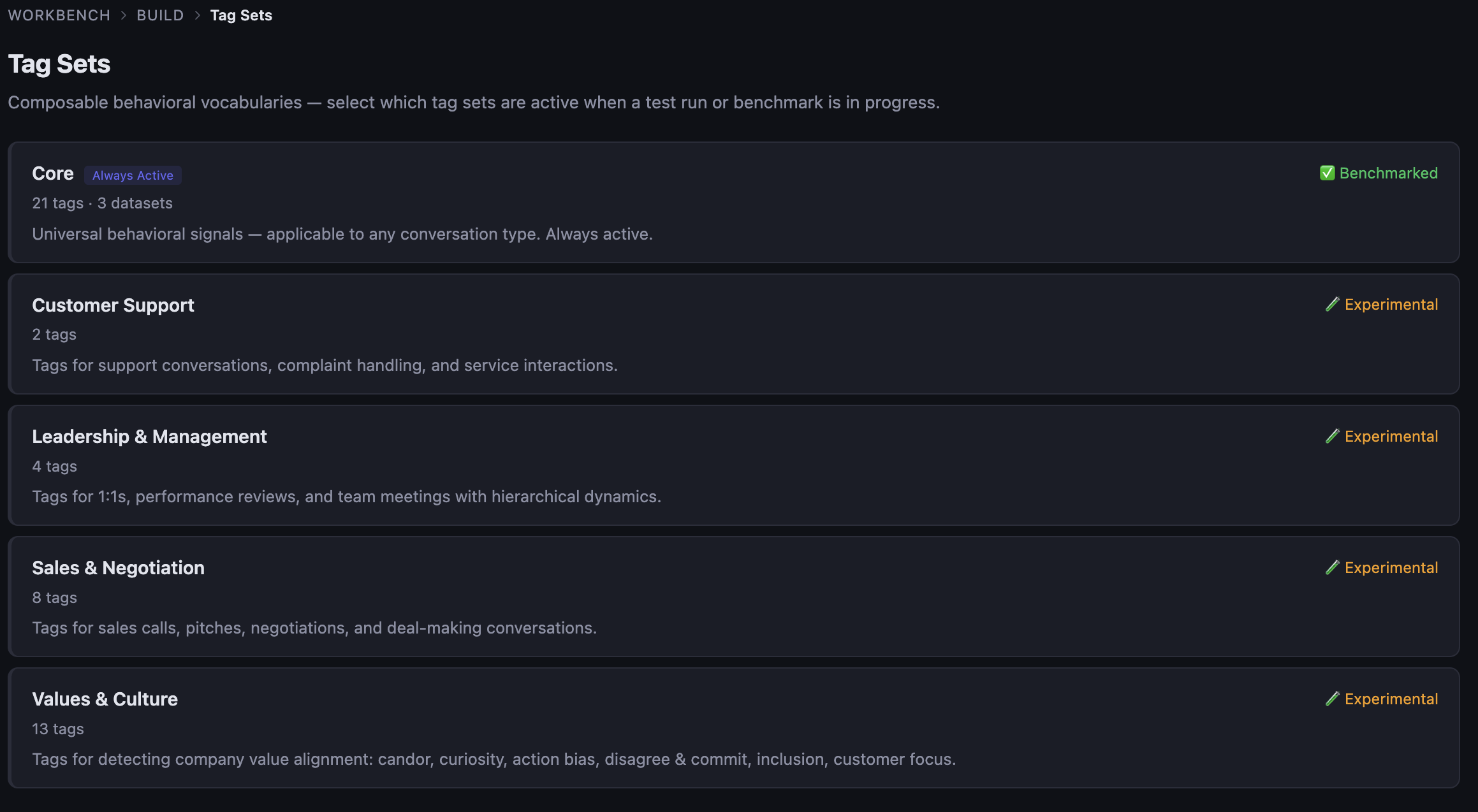
The vocabulary is the part of the system I'd argue matters most. It's the list of behaviours the pipeline can detect. Without it, you have nothing. With the wrong one, you get noise that erodes trust within a couple of runs.
The Core set is 21 tags. Universal stuff — emotions, communication patterns, collaboration moves, basic conflict signals. Always active, always benchmarked, the most stable part of the system. On top of Core, there are domain sets that load conditionally based on what kind of conversation is being analysed: Sales (8 tags), Leadership & Management (4), Customer Support (2), Values & Culture (13). When a run kicks off, you pick which sets are active and the model only ever sees those tags in its prompt.
The first version of this was different. One huge tag list, eighty-plus entries. It didn't survive contact with the model. Stuffing too many tags into one prompt confused the LLM in predictable ways: it conflated similar tags, missed obvious ones, hallucinated rare ones. Cutting down to Core plus domain modules brought the F1 numbers back, at the cost of more configuration logic in the pipeline.
The deeper reason to keep tag sets modular isn't really about accuracy though. It's about not generating noise. Detecting "closing" in a standup is just noise. Same for "delegation" in a support ticket. The conversation type tells you which sets are relevant; loading anything else gives you false positives that erode trust faster than missing detections do.
The datasets
Behavioural analysis has a corpus problem. Public datasets are heavy on sentiment and emotion. You can't really find one annotated with "did this manager listen to their report?" — those don't exist as public corpora. So the question becomes: what do you bench against?
Three datasets ended up doing most of the work for the Core set:
- MELD Emotions — multi-party dialogue from Friends, per-utterance emotion labels, ~200 cases. GPL-3.0. Useful for the emotional tags (frustration, anger, anxiety, enthusiasm).
- Empathetic Dialogues — Facebook Research, ~2,500 cases. 32 fine-grained emotion labels that I collapsed into the 10 emotional tags in Core. Apache-2.0.
- CaSiNo — campsite-negotiation dialogues with behavioural strategy annotations, ~400 cases. CC-BY-4.0. Useful for the collaboration and conflict-handling tags.
Four more datasets are imported but not yet benchmarked — Persuasion for Good (charity-donation conversations), CraigslistBargains, ESConv (emotional support), ProsocialDialog. Each one's annotations had to be mapped from its own taxonomy onto ours by hand. Deciding that "self-disclosure" in CaSiNo should map to one of our tags, or that it shouldn't map at all, is the actual work. It's where the vocabulary gets defined and defended.
For tags without a public dataset, the approach is hybrid: about 50 hand-validated samples per tag. Enough for a per-tag trust score. Not enough to claim production-grade confidence. That gap is honest, and I expect to be honest about it for a while.
How I know it works
Benchmarking is its own surface in the staff app. You pick a dataset and a set of pipelines, and the system runs every case through each pipeline. The pipeline never sees the ground-truth labels — that's a hard rule, not a guideline. (More on why in the next section.)
For each case, the scorer compares the pipeline's output against the ground truth at three levels:
- Per tag. True positives, false positives, false negatives. Precision, recall, F1.
- Per tag set. Aggregate F1 for Core, Sales, Support, and so on.
- Overall. Weighted F1 across the whole run.
A scoreboard ranks pipelines by F1. You can drill into any case and see transcript, ground truth, and pipeline output side by side. Cost and latency get tracked per case too — a pipeline that wins on F1 but costs three times as much per transcript doesn't necessarily win the deployment decision.
What didn't work
Three things, roughly in the order I noticed them.
Ground truth was leaking into eval, accidentally.
Early benchmark runs were producing F1 numbers that looked too good. The pipeline wasn't reading the ground-truth labels in its prompt — but the case object getting passed through the codebase contained both the input transcript and the ground-truth tags, and at some point the analysis code was reading the ground-truth half by reflex. Couple of layers deep. Once that got fenced off and the pipeline was made to take only CaseInput (transcript) and never CaseGroundTruth (tags), F1 dropped fifteen-or-so points. That's why the rule now is hard, not advisory: the pipeline literally cannot get the ground truth, ever, even by accident.
Privacy lived in the wrong place.
The staff tool started as a benchmarking surface — pipelines, tag sets, scoreboards. Around week four it had grown into the place where customer transcripts and tags were also being inspected, and the data layer below it had no boundary between "staff" and "customer". Anyone on staff could open any customer's data. The fix was a hard architectural split — staff R&D in one product, operational deployment in a separate one with proper access control. Should have written down who can see what before building anything that displayed customer data. I didn't. Cost me about a week to undo.
Quality scoring labels lied for a while.
Early outputs sometimes got labelled "high quality" that, on inspection, were thin or evidence-light. The labels were measuring something. They just weren't measuring what a user reading "high quality" would expect. Spent a week recalibrating both the metric and the words attached to it. Should have caught it sooner. The general thing here is that a label and the underlying number can drift apart and you won't notice unless you check, because you wrote both.
Where it stands
Three pipelines configured right now. A v6 production pipeline on Claude Haiku with signal extraction disabled, a v6 variant with signals enabled still in testing, and an older v2 default pipeline on Claude Sonnet. F1 is solid on the emotional Core tags, decent on collaboration moves, weakest on the conflict-handling tags where ground-truth coverage is thinnest. Good enough to demo. Not yet tight enough that I'd put it inside a real performance review. Another few weeks of focused work would probably close that gap, but the project's job at this point is to be a testbed for ideas, not to ship a product, and that's where it'll likely stay.
← All projects